Basic Git & GitHub for DevOps Engineers

I have 10+ years of experience in Project Management across a range of industries including Oil & Gas, IT, Retail, and Rail Transportation, I have developed a proven track record in delivering results while maintaining a positive and proactive approach to work responsibilities.
As I look to the future, I am excited to pivot my career towards the field of Technology as a Scrum Master with a DevOps Engineer skill-set. To achieve this goal, I am committed to acquiring a range of key skills, knowledge, and certifications including SAFe Scrum Master, SAFe DevOps Practitioner, and expertise in a variety of DevOps tools such as Linux, Git & GitHub, Networking, CI/CD (Jenkins), Docker, AWS, Terraform, Kubernetes, Prometheus, Grafana, Go, and Python. I am eager to bring my experience and passion to a new role as a DevOps Engineer and to make a valuable contribution to any team.
I am excited about the opportunities ahead and look forward to bringing my expertise, enthusiasm, and positive attitude to a new role. Thank you for taking the time to learn more about me, and I welcome the opportunity to connect and explore potential collaborations.
Git
As described by [www.git-scm.com] - "Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency."
It allows developers to track changes to their code over time and collaborate with other developers on the same project by providing features for sharing and merging code changes. When multiple developers are working on the same project, each developer can create a separate local repository and make changes without affecting the main codebase. Git offers tools to integrate these independent changes into a unified codebase and resolve any conflicts that may arise.
Git's capability to facilitate branching and merging is a prominent feature. By branching, developers can establish distinct lines of development within a codebase, which enables them to test new features or make changes without impacting the main codebase. Subsequently, merging allows developers to merge these separate lines of development back together into one unified codebase.
Git operates by establishing a local repository on your computer that houses the entirety of your project's code, complete with a comprehensive record of all alterations made to the code. Whenever a modification is made, Git generates a "commit" that captures the present state of the code and saves it within the local repository.
GitHub
A web-based platform, for storing and managing code repositories. It offers various tools and features for facilitating collaboration on software and code projects. It offers many features - to list a few:
Version control: It serves as a primary platform for version control, enabling developers to monitor alterations made to their code over time. This guarantees that every code version is preserved and accessible when required.
Collaboration: It furnishes various tools for multiple developers to collaborate on a project simultaneously. Developers can easily monitor modifications made to the code and work together by inspecting each other's code, proposing changes, and merging them.
Issue tracking: It provides an issue tracking mechanism that allows developers to report bugs, demand new functionalities, and monitor the advancement of tasks.
Documentation: It offers tools for documenting projects, such as wikis and README files, that assist in outlining the project's purpose, its functioning, and how to utilize it.
Version Control System and Types of Version Control Systems (VCS)
A version control system (VCS) is a tool that manages modifications to files over time, allowing developers to monitor all changes made to files and their versions. This enables them to easily revert to previous versions, compare changes, and collaborate with other developers on the same files at the same time. To operate, a VCS generates a repository that preserves all the files and their versions. Whenever a developer alters a file, the VCS documents the changes and generates a new version of the file. The developer can subsequently contrast the differences between versions and restore any previous version if necessary. Here are three types of VCS:
Local VCS - It is installed on a single developer's computer, keeping file versions on the developer's hard drive. It is user-friendly, however, it is unsuitable for collaborative projects because it does not support multiple users working on the same file concurrently.
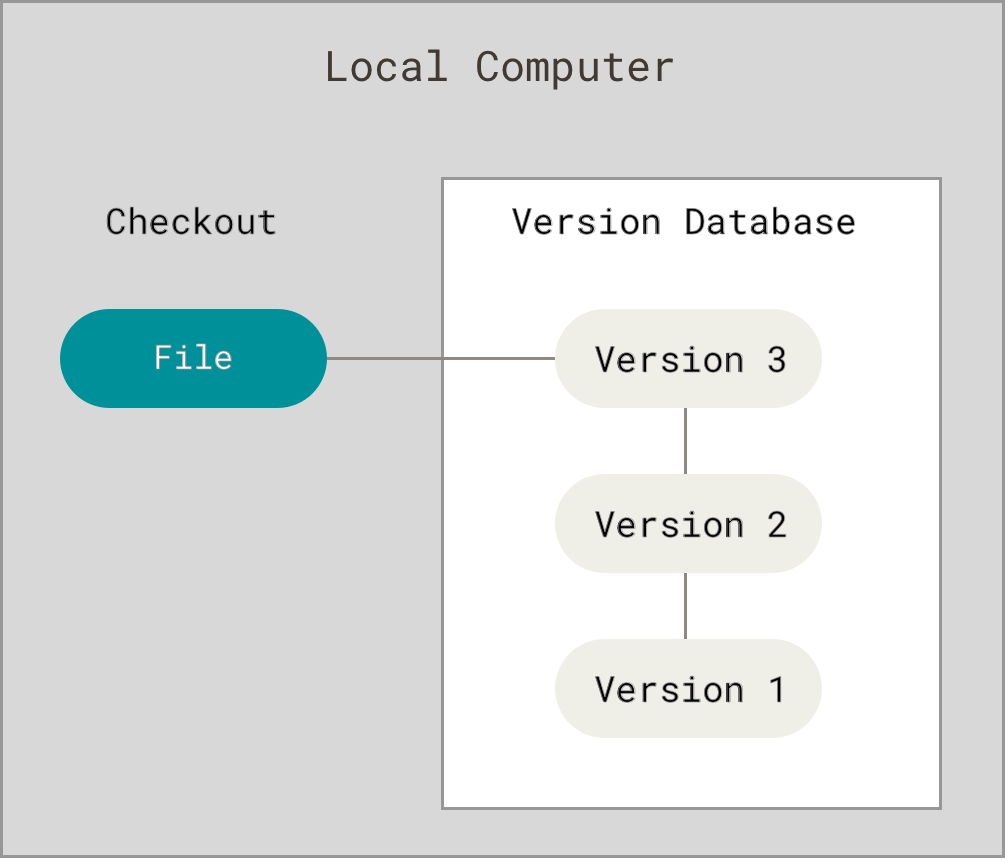
Centralized VCS - relies on a central server to save all files and their versions. Every developer retrieves the necessary files from the central server and modifies their local copy. When done, the changes are returned to the central server. While it promotes collaboration, the system has a single point of failure: the central server.
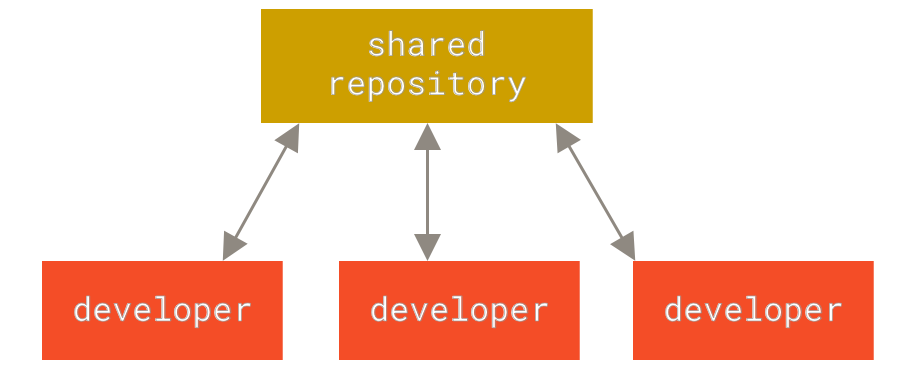
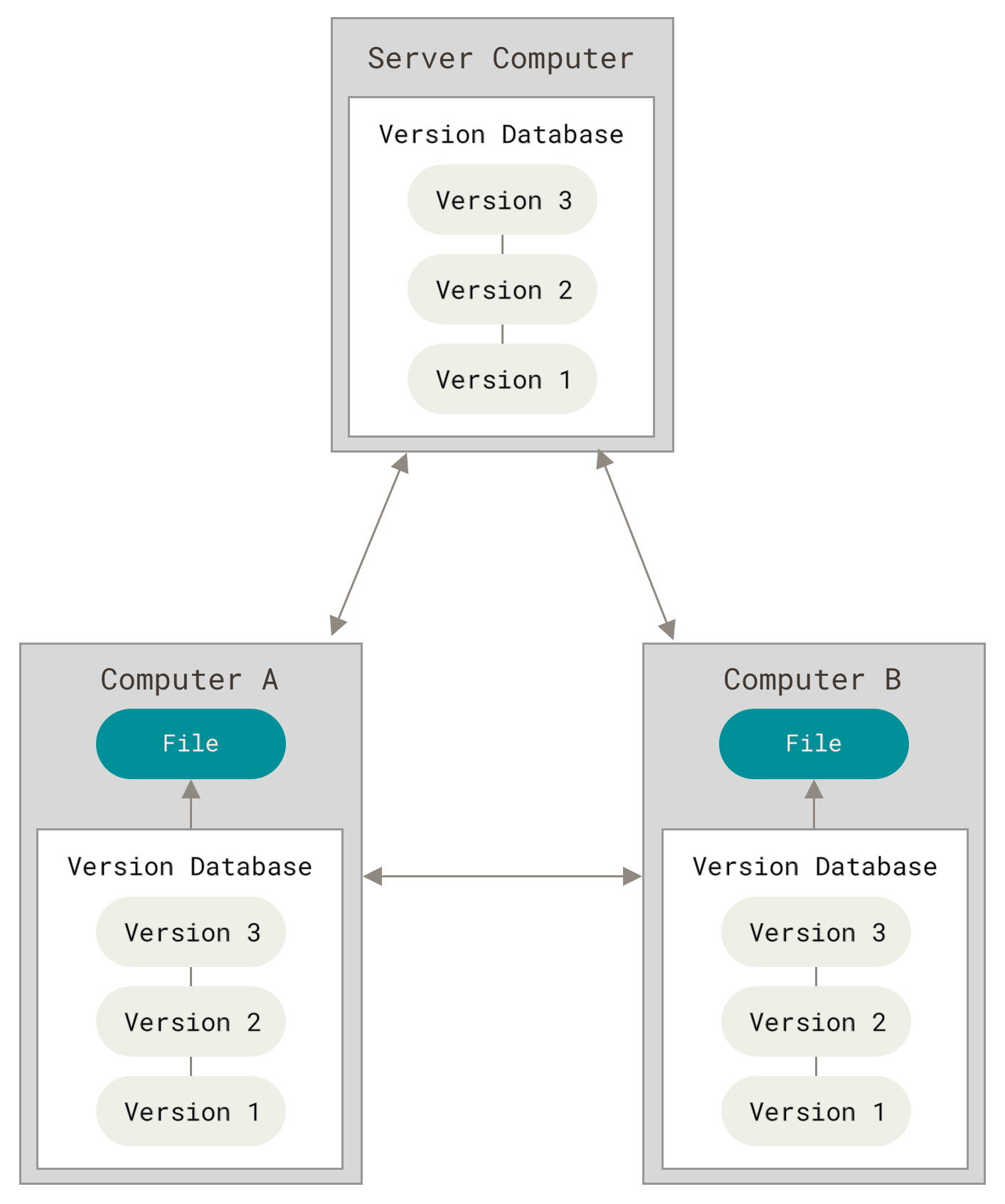
Distributed VCS - In this version control system, each developer has their own complete copy of the repository, containing all file versions, instead of depending on a central server like the CVCS. They can edit their local copy and merge it with other developers' copies once they are prepared. This system provides more flexibility, facilitates offline work, and is more resilient than centralized systems.
Why use Distributed VCS over Centralized VCS
Compared to a Centralized VCS, a Distributed VCS offers better flexibility, fault tolerance, and offline work capabilities, making it a preferable option for larger and distributed teams involved in software development.
Flexibility: In a Distributed VCS, developers can create separate branches for features/experiments, and merge them later. This provides flexibility to work on multiple tasks at once. Centralized VCS lacks this, requiring developers to work on the same branch, limiting flexibility and creating conflicts.
Fault tolerance: The Distributed VCS provides each developer with a complete copy of the repository, so if one copy is lost, it won't affect other developers' copies. In contrast, in a Centralized VCS, a corrupted central server can impact all connected developers.
Offline work: In a Distributed VCS, developers can work offline and make changes to their local repository copy, including all file versions. In a Centralized VCS, developers need to be connected to the central server to modify files.
Create a New Repo on GitHub & Clone it to a Local Machine
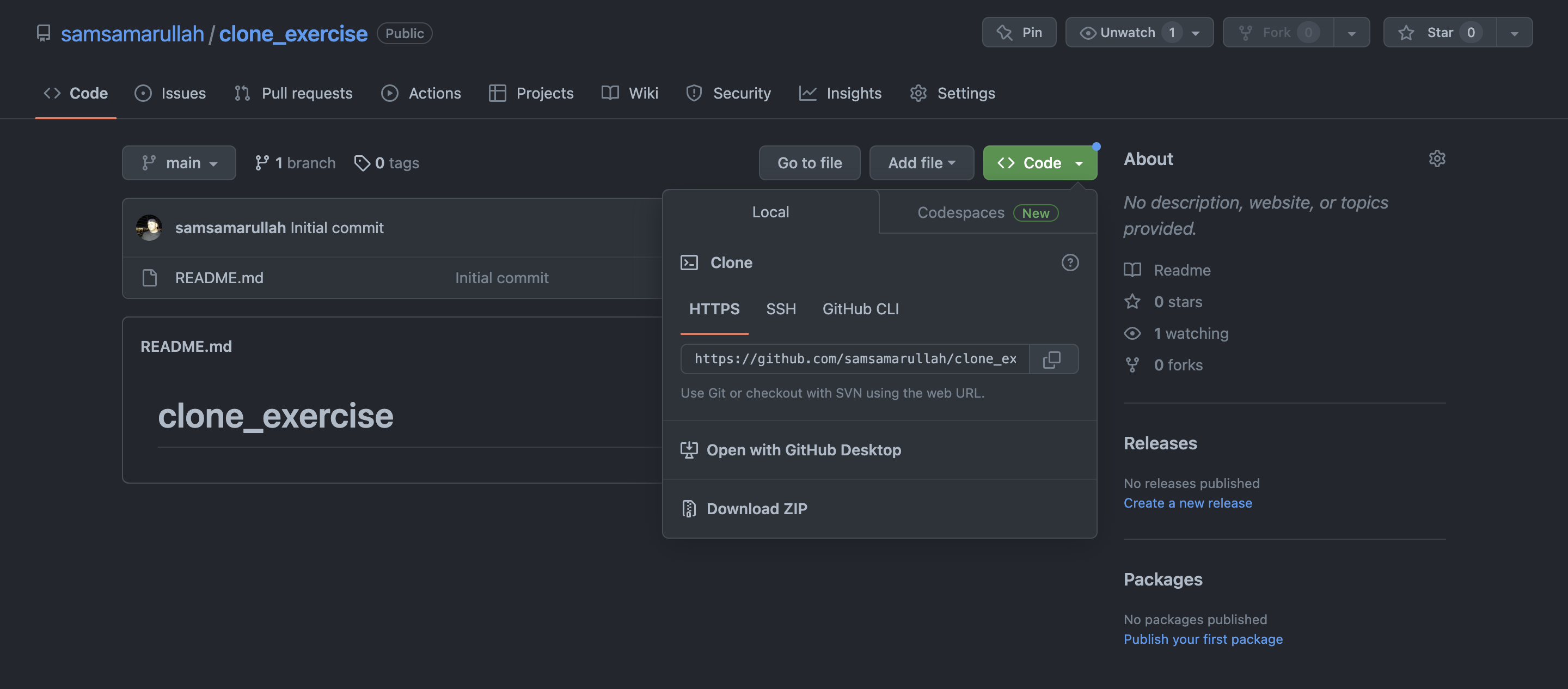
Once successfully logged into the GitHub account. Click on the "new" button to create your repo. Check the "Add a README file" to create a readme file in your remote repo and click on the "Create Repository" button. See below:

Once created, copy the repo URL to be used on your local machine. Once completed, move over to your Terminal in the directory where you want to clone your remote repo. Use the clone command: git clone "URL"
ubuntu@ip-172-31-61-13:~/test/test_for_clone$ git clone https://github.com/samsamarullah/clone_exercise.git
Cloning into 'clone_exercise'...
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Receiving objects: 100% (3/3), done.
ubuntu@ip-172-31-61-13:~/test/test_for_clone$
Changes to a file in the repo and commit to the repo using Git
I have created a test file and have used the command "git status" which currently shows that there is 1 untracked file - test_file.txt
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$ touch test_file.txt
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$ git status
On branch main
Your branch is up to date with 'origin/main'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
test_file.txt
nothing added to commit but untracked files present (use "git add" to track)
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$
To commit the test_file.txt, it needs to be tracked or staged first. I used the "git add test_file.txt" to stage it. Then once tracked, I used the "git commit -m "message" command to finally commit this file. Now if I run the "git status" command, the message I should get is "nothing to commit, working tree clean".
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$ git add test_file.txt
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: test_file.txt
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$ git commit -m "test_file.txt now committed"
[main 524cc05] test_file.txt now committed
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 test_file.txt
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$ git status
On branch main
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$
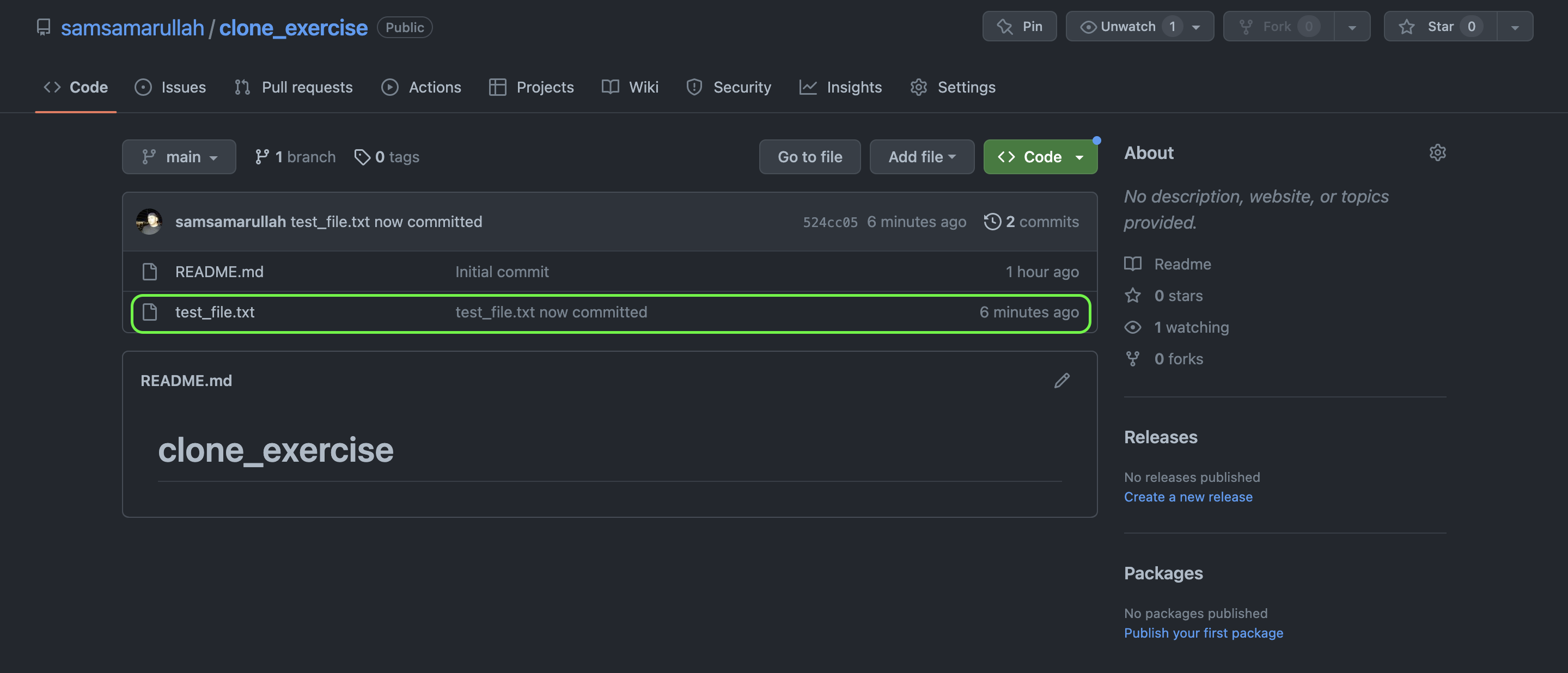
Now I will push the changes back to the remote repo on GitHub. I have used the "git push" command to perform this task. See the below Terminal code for this and have a look at the repo on GitHub showing the test_file.txt.
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$ git push
Username for 'https://github.com': samsamarullah
Password for 'https://samsamarullah@github.com':
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 285 bytes | 285.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To https://github.com/samsamarullah/clone_exercise.git
b9fe641..524cc05 main -> main
ubuntu@ip-172-31-61-13:~/test/test_for_clone/clone_exercise$
I appreciate your busy time reading this short blog. As I continue with my journey to learn and acquire the skill set of a DevOps Engineer, I will share what I learn. Thank you.
Happy Learning!




